












 Dan’s Biz Bookshelf: ‘Elevate: Push Beyond Your Limits'
Dan’s Biz Bookshelf: ‘Elevate: Push Beyond Your Limits' The Marketing Minute: The First Step to More Sales—Marketing
The Marketing Minute: The First Step to More Sales—Marketing It’s Only Common Sense: Customer Service Is Sales in Disguise
It’s Only Common Sense: Customer Service Is Sales in Disguise





DARPA Goes 'Meta' with Machine Learning for Machine Learning
June 20, 2016 | DARPAEstimated reading time: 2 minutes
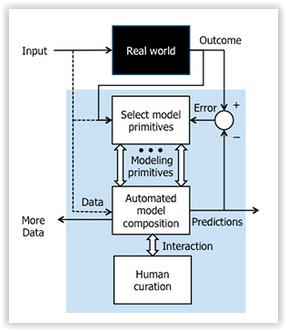
Popular search engines are great at finding answers for point-of-fact questions like the elevation of Mount Everest or current movies running at local theaters. They are not, however, very good at answering what-if or predictive questions—questions that depend on multiple variables, such as “What influences the stock market?” or “What are the major drivers of environmental stability?” In many cases that shortcoming is not for lack of relevant data. Rather, what’s missing are empirical models of complex processes that influence the behavior and impact of those data elements. In a world in which scientists, policymakers and others are awash in data, the inability to construct reliable models that can deliver insights from that raw information has become an acute limitation for planners.
To free researchers from the tedium and limits of having to design their own empirical models, DARPA today launched its Data-Driven Discovery of Models (D3M) program. The goal of D3M is to help overcome the data-science expertise gap by enabling non-experts to construct complex empirical models through automation of large parts of the model-creation process. If successful, researchers using D3M tools will effectively have access to an army of “virtual data scientists.”
“The construction of empirical models today is largely a manual process, requiring data experts to translate stochastic elements, such as weather and traffic, into models that engineers and scientists can then ask questions of,” said Wade Shen, program manager in DARPA’s Information Innovation Office. “We have an urgent need to develop machine-based modeling for users with no data-science background. We believe it’s possible to automate certain aspects of data science, and specifically to have machines learn from prior example how to construct new models.”
D3M is being initiated at a time when there is unprecedented availability of data via improved sensing and open sources, and vast opportunities to take advantage of those data streams to speed scientific discovery, deepen intelligence collection, and improve U.S. government logistics and workforce management. Unfortunately, the expertise required to build useful models is in short supply. Some experts project deficits of 140,000 to 190,000 data scientists worldwide in 2016 alone, and increasing shortfalls in coming years. Also, because the process to build empirical models is so manual, their relative sophistication and value is often limited.
A recent exercise conducted by researchers from New York University illustrated the problem. The goal was to model traffic flows as a function of time, weather and location for each block in downtown Manhattan, and then use that model to conduct “what-if” simulations of various ride-sharing scenarios and project the likely effects of those ride-sharing variants on congestion. The team managed to make the model, but it required about 30 person-months of NYU data scientists’ time and more than 60 person-months of preparatory effort to explore, clean and regularize several urban data sets, including statistics about local crime, schools, subway systems, parks, noise, taxis, and restaurants.
“Our ability to understand everything from traffic to the behavior of hostile forces is increasingly possible given the growth in data from sensors and open sources,” said Shen. “The hope is that D3M will handle the basics of model development so people can apply their human intelligence to look at data in new ways, and imagine solutions and possibilities that were not obvious or even conceivable before.”
Share on:




Suggested Items
Tightening of LPDDR4X Supply Drives Up Prices; Smartphone Brands to Accelerate Adoption of LPDDR5X
07/17/2025 | TrendForceTrendForce’s latest investigations reveal that major Korean and U.S. memory suppliers are expected to significantly reduce or even cease production of LPDDR4X in 2025 and 2026.
Beyond Design: Refining Design Constraints
07/17/2025 | Barry Olney -- Column: Beyond DesignBefore starting any project, it is crucial to develop a thorough plan that encompasses all essential requirements. This ensures that the final product not only aligns with the design concept but is also manufacturable, reliable, and meets performance expectations. High-speed PCB design requires us to not only push technological boundaries but also consider various factors related to higher frequencies, faster transition times, and increased bandwidths during the design process.
Knocking Down the Bone Pile: Addressing End-of-life Component Solderability Issues, Part 4
07/16/2025 | Nash Bell -- Column: Knocking Down the Bone PileIn 1983, the Department of Defense identified that over 40% of military electronic system failures in the field were electrical, with approximately 50% attributed to poor solder connections. Investigations revealed that plated finishes, typically nickel or tin, were porous and non-intermetallic.
Digital Twin Concept in Copper Electroplating Process Performance
07/11/2025 | Aga Franczak, Robrecht Belis, Elsyca N.V.PCB manufacturing involves transforming a design into a physical board while meeting specific requirements. Understanding these design specifications is crucial, as they directly impact the PCB's fabrication process, performance, and yield rate. One key design specification is copper thieving—the addition of “dummy” pads across the surface that are plated along with the features designed on the outer layers. The purpose of the process is to provide a uniform distribution of copper across the outer layers to make the plating current density and plating in the holes more uniform.
The Knowledge Base: A Conference for Cleaning and Coating of Mission-critical Electronics
07/08/2025 | Mike Konrad -- Column: The Knowledge BaseIn electronics manufacturing, there’s a dangerous misconception that cleaning and coating are standalone options, that they operate in different lanes, and that one can compensate for the other. Let’s clear that up now. Cleaning and conformal coating are not separate decisions. They are two chapters in the same story—the story of reliability.